
![]() Coming out of .NEXT 2017, we saw 3 major strategic announcements from Nutanix, as well as a number of smaller updates. Some of these had been previously announced, and some were all new. In this article, I’d like to give a quick overview on some of those smaller announcements or changes that didn’t get the press they may have deserved.
Coming out of .NEXT 2017, we saw 3 major strategic announcements from Nutanix, as well as a number of smaller updates. Some of these had been previously announced, and some were all new. In this article, I’d like to give a quick overview on some of those smaller announcements or changes that didn’t get the press they may have deserved.
First, lets review the big 3:
These 3 updates are the ones you’ll find all over the trade papers if you search on Nutanix. They are stealing the spotlight, but there are some other noteworthy things that came out of the show. Here are a few:
X-Ray
This is a pretty big one, and just about rates with the ones above. This is a new tool with general availability announced at .NEXT 2017 that automates benchmarking and testing. The basic driver behind the tool is that most of the workload generators people use today are pretty basic. Many of them tend to be storage focused, making it difficult to co-ordinate tests that really find boundaries within a connected system including many types of resources.
X-Ray is scenario driven, which is really cool. You can simulate things like:
- Node failures. I’ve had many customers try to test this. X-Ray automates it.
- Snapshot impact. Leave snapshots running for a long time. Automated.
- Co-location or workload interference. What happens if I collapse these 2 workloads onto 1 resource?
- Rolling upgrades. Do I have performance degradation during an upgrade?
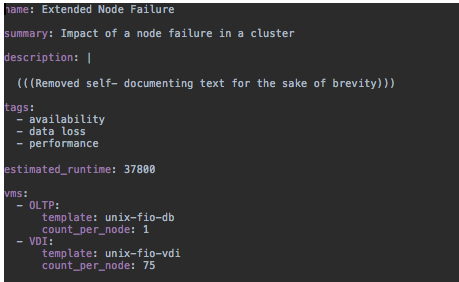
X-Ray is transparent. All the tests it runs are defined in an english YAML file (see above), so you know it isn’t doing something funky to favor Nutanix. It works against any infrastructure, so you can use this in your bake-offs and POCs to get better and more realistic performance information. I like it!
Here is a nice blogpost on it from Nutanix: https://next.nutanix.com/t5/Nutanix-Connect-Blog/Why-X-Ray/ba-p/21678
Check out the official page, or run it yourself here: https://www.nutanix.com/xray/
AHV Turbo Mode
This is a change in how Nutanix clusters run IO in AHV environments. Quite contrary to many people’s expectations, this does NOT mean the IO path now runs “in-kernel.” It sounds to me like they actually have a bunch of IO threads spin up in userspace to increase the number of queues, among other benefits. Some of the real world impacts of this change include 25% lower CPU usage and 33+% better random write performance.
This is a software change that is really well positioned to take advantage of future hardware improvements such as NVMe and 3D XPoint.
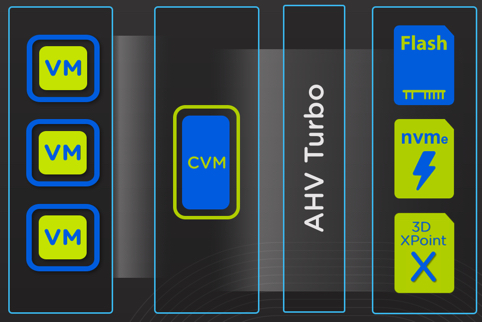
Learn more about this on this Nutant blog.
Async Replication RPO Reduced to 1 Minute.
This will allow much more granular replication cycles for overall improved data protection and disaster recovery.
1 Node and 2 Node solutions.
Nutanix has had a single node solution available for a while. This was largely a data protection play, so think of it as a destination for protection or backup data. They have now also announced 2 node solutions, which makes a Nutanix solution competitive in the ROBO or Edge space.
One Click Networks.
GUI configuration of micro-segmentation and network provisioning. Network mapping/visibility. I expect some of the open networking partners to jump all over this to create added integration here.
That’s just a brief update on a few of the more interesting announcements out of .NEXT. What do you think about these changes? Did I miss any? Let me know in the comments below (under related posts).
[…] Other Smaller Announcements […]
[…] Other Smaller Announcements […]